(754)
Datadog est une plateforme unifiée d'observabilité et de sécurité pour les applications cloud à grande échelle.
Datadog est une plateforme unifiée d’observabilité et de sécurité pour les infrastructures et applications cloud-scale. Elle offre des fonctionnalités de monitoring, d’analyse des logs, de gestion de performance des applications et de sécurité. La solution est conçue pour aider les équipes DevOps et sécurités à détecter et résoudre rapidement les incidents.
🎯 Idéal pour : les entreprises cloud et DevOps cherchant une visibilité en temps réel sur leur stack technique.

Datadog est une plateforme SaaS tout-en-un dédiée à l’observabilité des systèmes IT modernes. Développée par l’entreprise Datadog, Inc., elle permet un monitoring unifié des infrastructures, applications, logs, performances et sécurité. Son objectif principal : centraliser les données pour aider les équipes DevOps, SRE et IT à identifier rapidement les anomalies.
Fondée en 2010 à New York, l’entreprise a progressivement consolidé sa présence sur le marché avec une croissance soutenue, adressant les besoins des systèmes distribués complexes. Datadog se distingue par sa capacité à s’intégrer à plus de 600 technologies (AWS, Kubernetes, Azure, Docker…) et par une interface intuitive malgré la densité d’informations affichées.
Le logiciel opère en mode SaaS, ce qui facilite le déploiement et la scalabilité. Son marché cible inclut principalement les entreprises à forte maturité cloud, orientées CI/CD et microservices. Aujourd’hui, Datadog est reconnu comme un acteur majeur du monitoring moderne, souvent comparé à des concurrents comme New Relic, Dynatrace ou Splunk.
Lors de notre test de Datadog, nous avons exploré ses modules clés, notamment Infrastructure Monitoring, Log Management, APM et Security Monitoring. L’approche modulaire de la plateforme permet d’activer uniquement les briques nécessaires, ce qui s’adapte à différents niveaux de complexité.
Nous avons connecté un cluster Kubernetes, simulé des erreurs applicatives et analysé les journaux produits par nos services. La richesse des métriques collectées et la visualisation dynamique dans les tableaux de bord ont été particulièrement appréciées. Il faut toutefois un temps d’adaptation pour appréhender la logique de tags et les permissions d’équipe. Chaque fonctionnalité testée reflète une volonté de centralisation et d’automatisation poussée du monitoring.
Connexion fluide à nos instances AWS et GCP, affichage en temps réel des métriques clés avec des alertes personnalisables très puissantes.
Suivi précis des requêtes HTTP et des temps de réponse. Nous avons pu isoler facilement un endpoint dégradé dans notre API.
Centralise les logs dans une interface graphique. Recherche intuitive, filtrage par tags très utile pour identifier des erreurs.
Détection d’événements suspects dans notre pipeline CI/CD, alertes en temps réel sur des comportements de conteneurs anormaux.
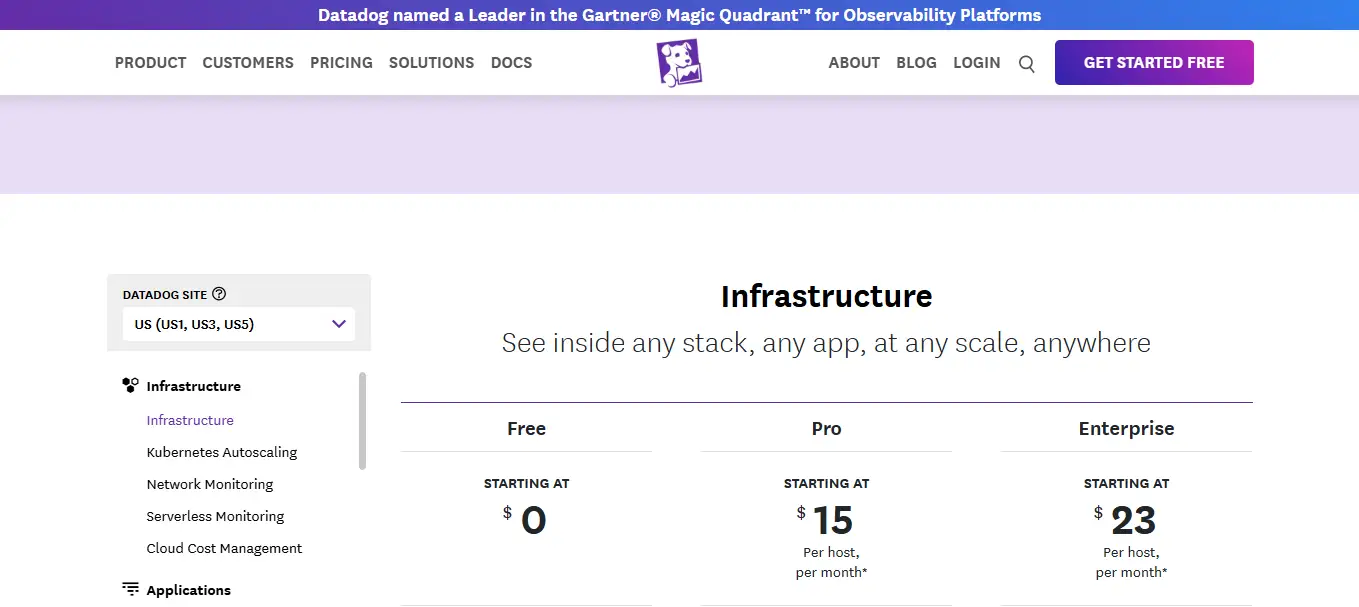
La politique tarifaire de Datadog repose sur une facturation modulaire, fonction du nombre d’hôtes monitorés, des logs indexés ou encore des utilisateurs. Les prix débutent à 15 dollars par hôte/mois pour l’infrastructure monitoring, et peuvent grimper à 31 dollars pour le module APM. Le log management est facturé par volume ingéré puis indexé, ce qui peut rapidement devenir coûteux.
En comparaison, des concurrents comme New Relic proposent un modèle all-in-one avec utilisateurs illimités, ou encore Sentry (pour l’APM & logs orienté dev) à des tarifs plus accessibles.
Le principal défaut de cette grille est sa complexité. Il devient difficile d’estimer précisément le budget annuel sans un audit précis des volumes. Il faut donc bien calibrer l’usage via des quotas ou des alertes budgétaires.
Le ROI reste pourtant élevé si l’on exploite au maximum les fonctionnalités, en particulier dans des systèmes critiques où le coût d’une panne dépasse largement celui de l’abonnement.
Datadog brille par plusieurs qualités concrètes. Sa richesse d’intégrations (plus de 600) permet une mise en place rapide dans des stacks variées. Nous avons connecté AWS, Docker et Redis sans configuration complexe.
La visibilité centralisée assure un gain de temps énorme : au lieu de jongler entre plusieurs outils, nous avons tout regroupé dans une interface uniforme, avec des dashboards personnalisables.
Le système d’alerting est particulièrement évolué : seuils dynamiques, corrélation entre logs et métriques, alertes sur anomalies statistiques avec ML.
Enfin, la performance de la plateforme elle-même : rapidité d’affichage, haute disponibilité, support client très réactif lors de notre test. Ces points expliquent pourquoi Datadog est souvent recommandé dans les grandes équipes DevOps.
Malgré ses qualités, Datadog présente plusieurs limites. Sa complexité initiale peut rebuter : la logique de tagging, les permissions d’équipe, ou encore la configuration d’exploration des logs demandent un réel apprentissage.
Le coût cumulé des modules est un autre point critique. Il est facile de démarrer, mais les volumes grandissent vite et le budget s’envole. Sans outils de contrôle de facturation, le TCO peut dépasser ses concurrents.
La documentation est exhaustive mais parfois trop dense pour débuter efficacement sans assistance. Des tutoriels interactifs pourraient améliorer la prise en main.
Les avis Datadog sur G2 et Capterra reflètent clairement la qualité perçue par les utilisateurs. Avec une note de 4.3/5 sur G2 (750+ avis) et 4.5/5 sur Capterra (135+ avis), la moyenne s’établit à 4.4/5. Cela le situe largement au-dessus de la moyenne des solutions concurrentes comme Splunk (souvent entre 4.1 et 4.3), et au niveau de Dynatrace.
Les utilisateurs saluent surtout la profondeur fonctionnelle, la scalabilité et le support technique. En revanche, plusieurs avis mentionnent la difficulté de compréhension tarifaire et la complexité initiale d’usage.
Trustpilot est peu utilisé dans le secteur B2B tech, ce qui explique son absence de note fiable. Dans l’ensemble, les évaluations Datadog confirment notre propre opinion : un outil puissant, mais réservé aux équipes matures en monitoring cloud.


Datadog s’impose comme une solution de référence pour le monitoring des systèmes distribués. Notre évaluation complète confirme sa justesse fonctionnelle et son intelligence d’intégration. Nous le recommandons sans réserve pour les entreprises ayant au moins une équipe DevOps structurée, fonctionnant dans une logique de cloud natif et d’orchestration dynamique (Kubernetes, CI/CD).
Pour ces profils, Datadog permet une unification des logs, métriques et traces très précieuse. Les économies en temps de debugging et le monitoring prédictif apportent un ROI solide à moyen terme.
En revanche, pour des organisations aux stacks monolithiques, ou peu familières avec les pratiques SRE, la courbe d’apprentissage et le coût global peuvent constituer une barrière.
Des alternatives comme New Relic (plus packagé), Sentry (plus développeur-centric) ou Prometheus/Grafana (open-source mais plus complexe) peuvent être plus adaptées selon les cas.
Notre recommandation : pour les environnements complexes et exigeants, Datadog est un excellent choix. Bien calibré, il devient un atout stratégique dans la performance et la fiabilité de vos systèmes IT. Une plateforme qui allie puissance technique et profondeur métier.