(7)
Infrastructure GPU à la demande pour les workloads d’IA
RunPod propose une infrastructure GPU à la demande optimisée pour l’entraînement et l’inférence de modèles d’IA. La plateforme offre une large gamme de GPU haute performance avec facturation à l’utilisation. Elle permet de déployer rapidement des environnements ML flexibles et évolutifs.
🎯 Idéal pour : chercheurs et développeurs d’IA recherchant une infrastructure GPU flexible et scalable.

RunPod est une plateforme cloud spécialisée dans l’hébergement GPU à la demande, principalement destinée aux développeurs IA/ML, chercheurs et créateurs de contenu nécessitant une puissance de calcul élevée. Contrairement aux fournisseurs traditionnels comme AWS ou Azure, RunPod se concentre exclusivement sur la fourniture de GPU performants et abordables, optimisés pour des workloads intensifs comme le deep learning, le rendu vidéo ou la simulation physique.
Accessible directement depuis un navigateur, RunPod permet de lancer des environnements GPU en quelques minutes, en choisissant son framework (comme PyTorch ou TensorFlow) et ses ressources. Ce positionnement ‘GPU-only’ en mode serverless ou persisté en fait une alternative économique, rapide et simple à déployer dans des contextes critiques.
La plateforme séduit notamment par ses performances constantes, sa transparence tarifaire et sa communauté active, ce qui en fait un acteur émergent crédible dans le secteur du cloud computing spécialisé GPU.
Lors de nos essais sur plusieurs workloads IA (entraînement de modèles, génération d’images, simulation physique), nous avons exploré les principales fonctionnalités de RunPod. L’expérience s’est révélée très intuitive malgré une UX technique. Nous avons utilisé une instance RTX 4090 avec 1 To de stockage persisté pour manipuler différents frameworks. Les outils de monitoring et de contrôle des ressources sont simples mais efficaces. Nous avons apprécié la logique ‘serverless versus persistent’ GPU, qui offre une vraie flexibilité de facturation et de gestion. Certaines fonctions avancées sont accessibles via l’API uniquement, un point à noter pour les équipes DevOps.
Permet de lancer des GPU à la demande via containers. Démarrage en 2 minutes et facture à la seconde. Idéal pour tester un modèle rapidement.
Instances GPU avec stockage et états préservés. Nous avons entraîné un modèle stable diffusion pendant 24 heures sans interruption.
Création d’environnements clé-en-main via Docker pour reproduire des workflows IA. Très utile pour les équipes ML collaboratives.
Connexion sécurisée entre pods pour créer une architecture distribuée. Nous avons pu déployer un cluster ML en interne facilement.
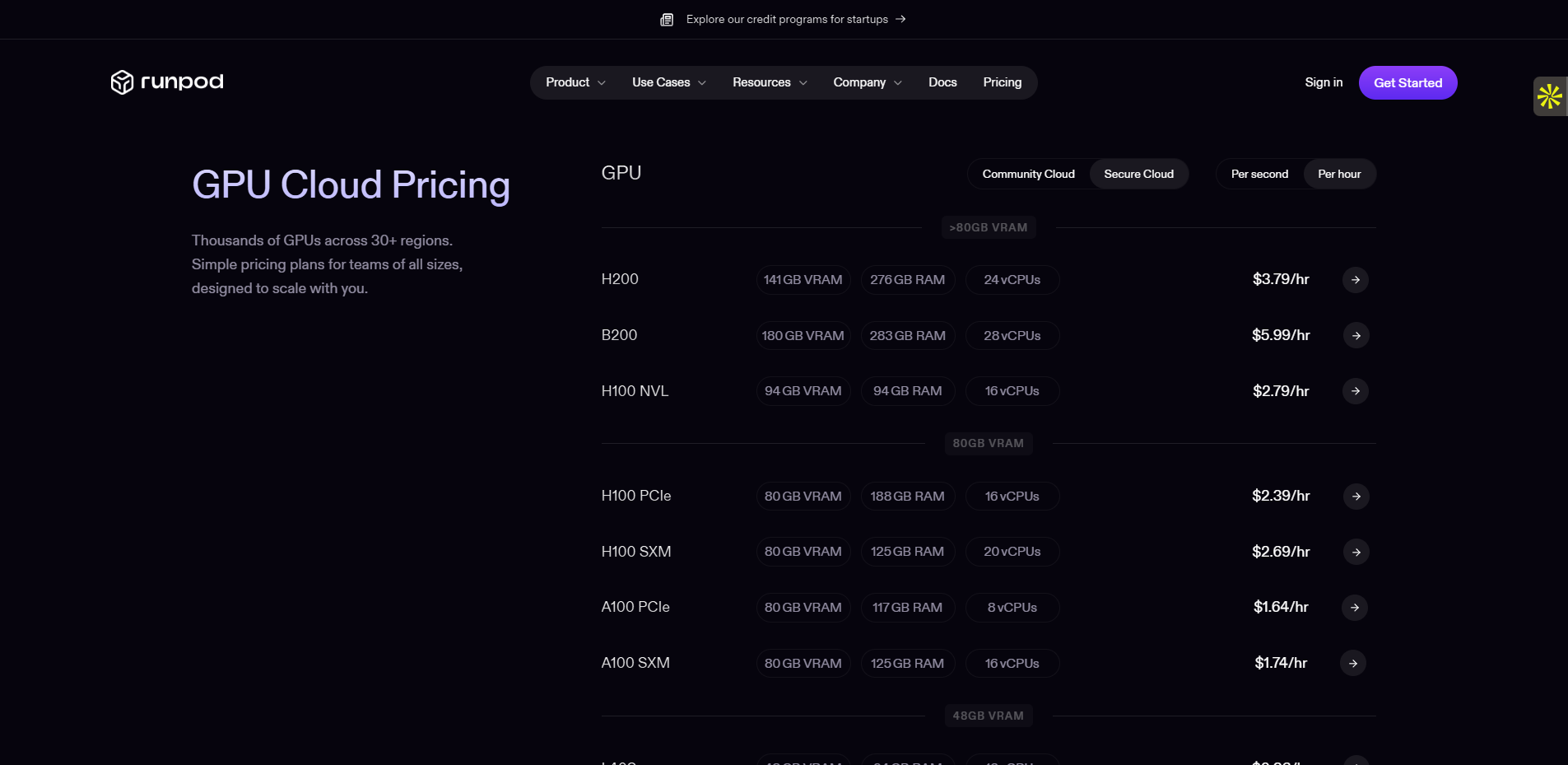
La tarification de RunPod est l’un de ses plus gros atouts. Le modèle est simple : paiement à l’heure selon le GPU, en mode serverless ou persistant. Un pod RTX 4090 coûte 1.05 euros/heure en moyenne, quand AWS EC2 avec GPU équivalent oscille à 2.40 euros/heure.
Il n’y a pas de frais cachés, le stockage et les egress sont transparents. Le mode serverless ne génère aucun coût si le pod est inactif. Des réductions sont disponibles via la mise en favoris (preferred compute), optimisant les taux horaires.
Comparé à Vast.ai ou Lambda Labs, RunPod reste compétitif. Vast offre parfois un coût inférieur, mais au prix d’une complexité accrue de gestion. RunPod propose un bon équilibre entre simplicité et performances. Côté ROI, le calcul est très favorable : le coût d’un entraînement long est maîtrisé, sans surcoût réseau.
On regrette seulement l’absence d’abonnement ou de forfaits plafonnés mensuels, ce qui peut freiner des structures au budget fixe. Mais globalement, c’est l’un des meilleurs rapports qualité/prix sur le marché du GPU cloud.
RunPod marque des points sur plusieurs aspects clés. La flexibilité du modèle serverless vs persistent permet d’adapter les dépenses au cas d’usage. Sur des lancements fréquents de modèles, l’économie réalisée est significative.
Le démarrage rapide et l’interface dépouillée sont parfaits pour un utilisateur technique. En 5 minutes, notre environnement ML était fonctionnel.
La transparence tarifaire – sans coûts cachés en data out ou surcharge – est un vrai soulagement comparé aux grands fournisseurs cloud.
La variété de modèles GPU disponibles (RTX 3090, A100, L40s…) sur plusieurs pays garantit une bonne disponibilité.
Enfin, la logique d’infrastructure as code et API facilite l’intégration dans un workflow CI/CD ML. RunPod s’intègre bien dans une architecture ML moderne, sans tomber dans la complexité excessive.
RunPod a toutefois quelques limites. L’interface est assez froide et non guidée pour un utilisateur moins aguerri : pas de wizards, peu de tutoriels intégrés. Le support par Discord est réactif mais non professionnel.
L’absence de prévisualisation GPU disponible en temps réel peut retarder certains déploiements. De plus, la suppression de pods n’est pas immédiate : un délai d’attente est requis.
Autre point : les custom templates nécessitent Docker + YAML, ce qui peut rebuter. Un éditeur visuel ou modèle communautaire serait un vrai plus. Enfin, pas de chiffrage natif des volumes, ce qui freine les projets sensibles.
Les avis RunPod sur les principales plateformes sont largement positifs. Sur G2, RunPod obtient 4.6/5 pour 18 avis, avec des éloges sur le coût, la rapidité de lancement et l’absence de surcharge. Les utilisateurs soulignent la fluidité du workflow IA. Sur Capterra, on compte actuellement peu d’avis (note : 4.6/5). Trustpilot n’a, à ce jour, aucun avis répertorié – logique pour un produit technique B2D.
Comparé à Vast.ai ou Lambda Labs, RunPod se distingue par une meilleure UX et une flexibilisation tarifaire appréciée. Le terrain est encore jeune, mais les notes RunPod reflètent une adoption croissante et positive dans la niche des clouds GPU.
Ainsi, pour rechercher des opinions fiables sur la fiabilité, la rapidité ou la transparence, les avis RunPod sur G2 sont les plus pertinents actuellement.


En conclusion, RunPod s’impose comme une alternative spécialisée et crédible aux géants du cloud quand il s’agit d’exploiter des GPU haute performance. Nous recommandons RunPod sans hésitation aux développeurs IA, chercheurs, studios graphisme ou start-ups ML ayant besoin de performance et de maîtrise budgétaire.
Attention toutefois : RunPod demande une certaine compétence technique pour en tirer pleinement partie. L’absence d’encadrement UX ou support SLA peut freiner des structures sans DevOps dédié.
Par rapport à Vast.ai (prix plus bas mais instable) ou Lambda Labs (plus industrialisé mais complexe), RunPod réussit son positionnement : simple, abordable, flexible.
Pour toute équipe expérimentée en IA/Dev souhaitant entraîner des modèles ou rendre des assets GPU sans friction logistique, nous disons oui à RunPod.
Notre recommandation est donc claire : RunPod est un choix excellent pour des usages ciblés, avec un ROI élevé. Il ne remplacera pas un cloud généraliste, mais il l’emporte largement sur son segment.